I have been recently working on and with LLMs like the million others in the world. There is a new model or an optimised version of an existing model that is released every day. People are not able to keep track of the changes that are happening. Each model claims to be different and better in terms of quality or scale or size than the other.
I stumbled upon a site which gives a good comparison of the output from multiple models. https://gpt.h2o.ai/
I wanted to try it out and just wrote “tell me a story about a dog” (yes, I am a dog lover).
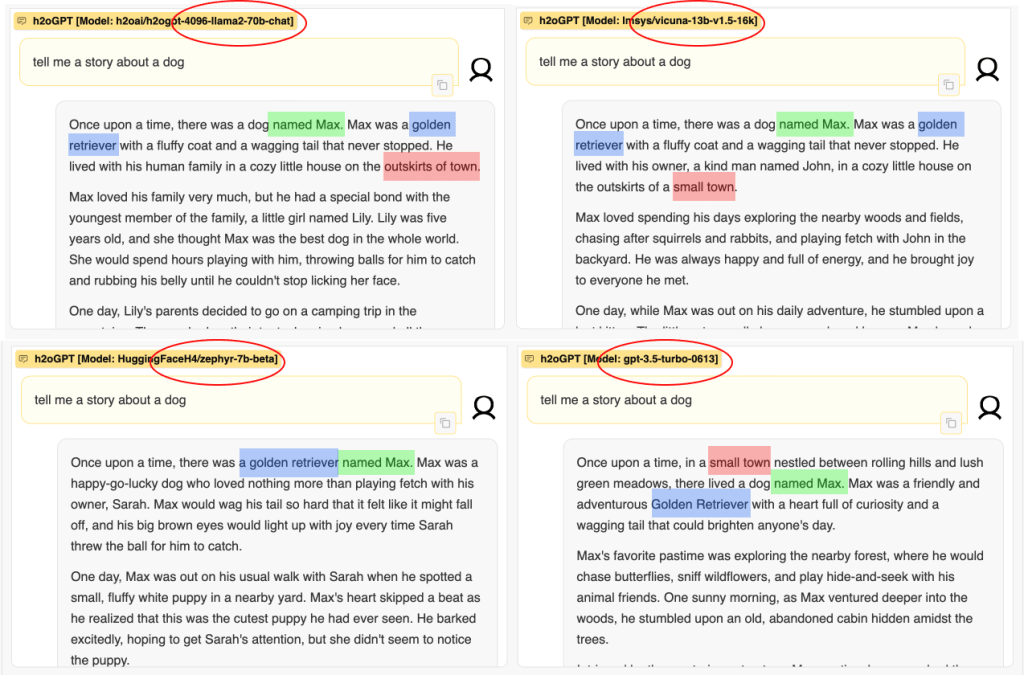
It was executed across 4 models with diverse backgrounds.
- Llama2-70b-chat – It’s a cool model built by Meta AI. BTW it’s a foundational model.
- Vicuna-13b-v1.6 – It’s like a fancy version of Llama2, fine-tuned by LMSYS.
- Zephyr-7b-beta – It’s a newer model based on Mistral-7B, fine-tuned by the awesome Hugging Face H4 team. Mistral-7B is a foundational model developed by Mistral AI.
- GPT-3.5-Turbo-0613 – The most popular and ground-breaking model built by Open AI that arguably started off this LLM fever. It’s again a foundational model.
So we can say 3/4 of these models are from different foundational models. Foundational model means it’s built from scratch and its trained over a large corpus of data. The data could be from the Internet, books and so on.
Now comes the interesting part…
All the models talked about a dog named Max.
All the models said the dog is a Golden Retriever
Three out of four models said that the dog lived in a small town.
Three out of four models said the dog’s owner was a female.
Is it just a probability game?
It makes sense if a fine-tuned model and its base model speak in similar ways. But its strange for two entirely independent foundational models to speak in exactly similar ways. This would mean that
- The models may not really foundational.. (Ohhh did I touch a sensitive nerve??)
- Or, the data given for training is so similar that there is no big difference in the model output.
- Or, dogs are named only Max. 🙂
So what?
I hope we don’t get into a world where each model copies from the other and all we have is a restrictive view of everything. The Internet came in to tell us more about everything but now is known for creating a bubble around each one of us. That said, it’s probably unfair to expect the GenAI models, which are offsprings of the Internet to be any better/different.
